BYBCTF Reverse2
前情提要:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string e="fmcdducnVnj`~eeOp~wg~|qtd";
int key=0;
int a,b,c,d;
for(int i=0;i<=26;i++)
{
e[i]=e[i]^key;
key++;
//key=~key;
printf("%c",e[i]);
}
return 0;
} //fmcdducnVnj`~eeOp~wg~|qtd
//dtq|~gw~pOee~`jnVncuddcmf汇编代码中的
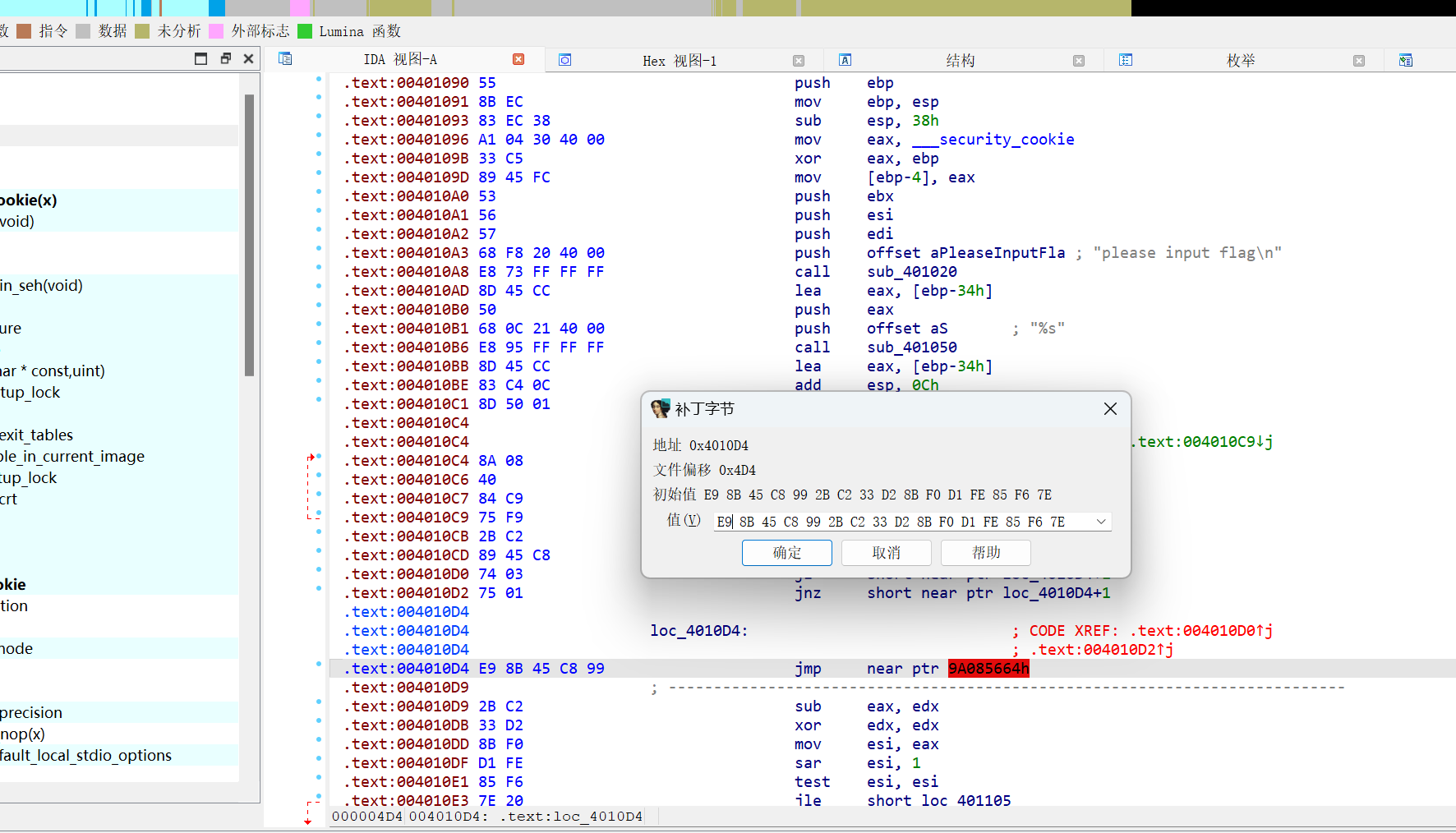
convert函数的作用是将源字符串src的每个字符与一个递增的计数器进行异或运算,然后将结果存储到目标字符串dest中。这个计数器从 0 开始,每次迭代增加 1,直到处理完指定的长度length为止。 具体步骤如下:
- 初始化计数器
i为 0。- 进入一个循环,循环的条件是
i小于length。- 在循环内部,执行以下操作:
- 将
i的值移动到edx寄存器。- 将
src的地址加上i的值,得到src中第i个字符的地址,并将其存储在edx寄存器中。- 从
edx指向的内存地址中取出一个字节(即src中的第i个字符),并将其存储在edx寄存器中。- 将
edx(即src中的第i个字符)与ebx(即计数器i)进行异或运算,结果存储在edx中。- 将
edx中的结果(即异或后的字符)存储到dest的第i个位置。- 将计数器
i增加 1。- 循环结束后,在
dest字符串的末尾加上一个终止符\0。 这个函数的目的是对字符串进行一种简单的加密或编码操作,通过异或运算来混淆字符串的内容。由于异或运算的特性,相同的操作可以用来解密或解码字符串,这就是为什么我们可以编写一个逆向函数来恢复原始字符串。
int main() { char p[] = { 102, 109, 99, 100, 127, 100, 117, 99, 110, 86, 110, 106, 96, 126, 101, 101, 79, 112, 126, 119, 103, 126, 124, 113, 116, 100 }; int length = sizeof(p) / sizeof(p[0]); convert(p,length); puts(p); return 0; }
来自远古时期的XOR代码,一条能将就绝对将就的懒狗
初看题目不难看出来是异或,原文也明摆在附件里
于是直接跑了一下附件里的主函数,得到了“原文字符串”
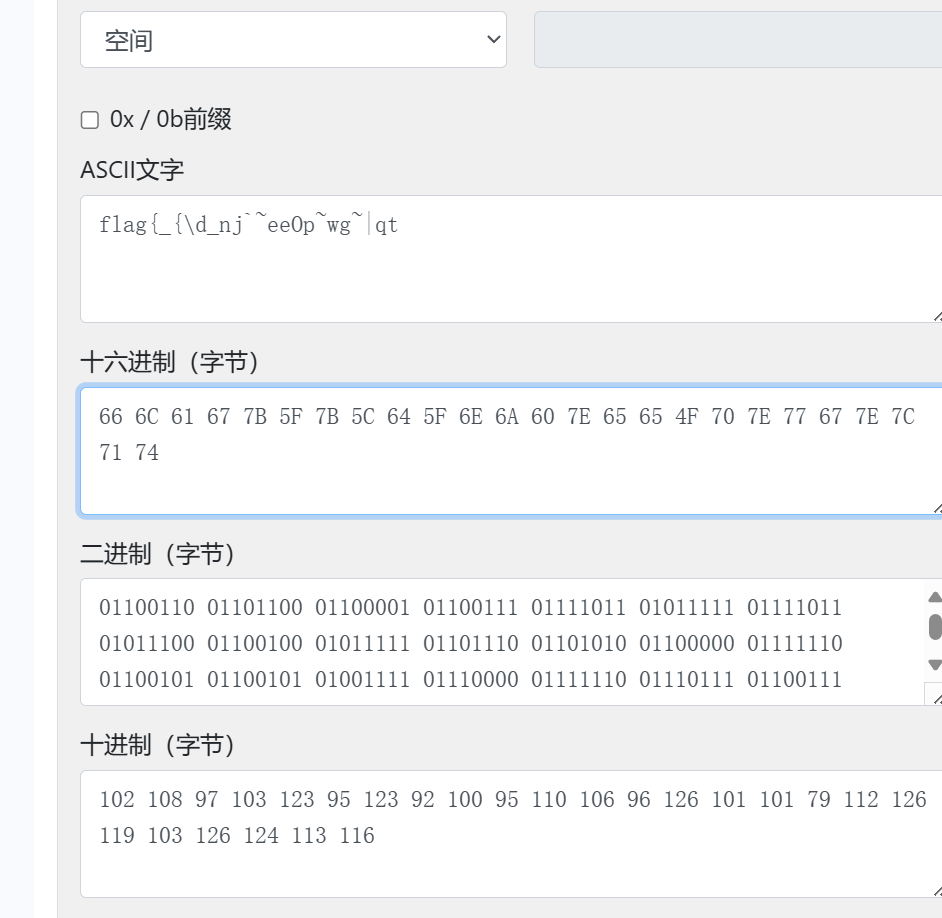
fmcdducnVnj`eeOpwg~|qtd
然后套进古老的XOR代码里,不出所料的跑出来了一个非常具有迷惑性的错误答案
flagpei^gkrhk@oetjigc|
由此走上了一条歪路,开始尝试根据flag格式和前四位手动计算其偏移量/异或数来手撕flag
但是实际上,这道题的异或操作是直接对其字符数组进行的:
#include<stdio.h>
void convert(char* input,int length)
{
int i;
for(i=0;i<length;++i)
{
input[i]^=i;
}
}
int main()
{
char p[] = { 102, 109, 99, 100, 127,
100, 117, 99, 110, 86,
110, 106, 96, 126, 101,
101, 79, 112, 126, 119,
103, 126, 124, 113, 116,
100 };
int length = sizeof(p) / sizeof(p[0]);
convert(p,length);
puts(p);
return 0;
}
错误点分析:
在一开始的时候就想当然的添上了一步十进制转ASCII的操作,之后又因为本来的脚本是这样就一直对字符串进行操作,一步错,步步错
要忠实于原题!