Samsetningar de 8086 Chap.I
一、寄存器
8086CPU有14个寄存器
分别是AX,BX,CX,DX,SI,DI,SP,BP,IP,CS,SS,DS,ES,PSW
8086CPU的所有寄存器都是16位的,可存放两个字节/一个十六位的数据
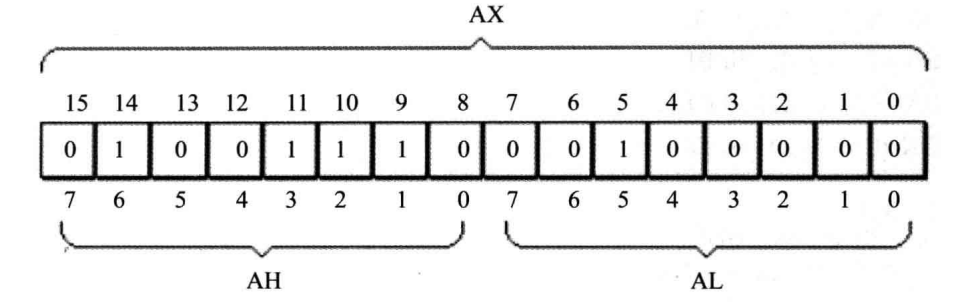
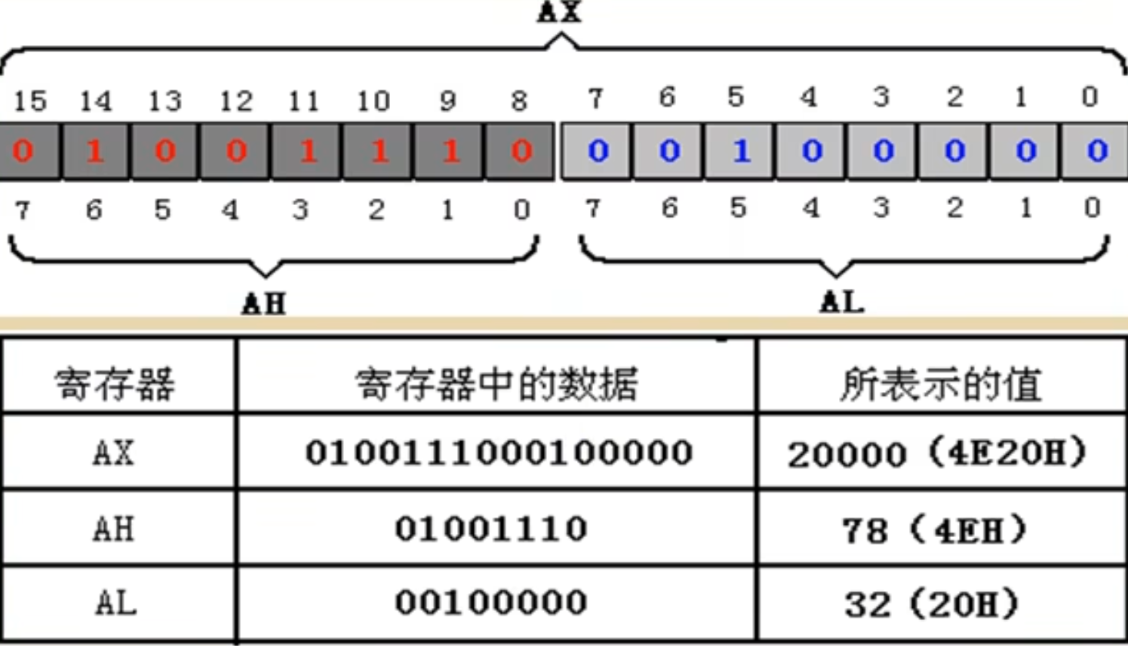
1.1 通用寄存器
被用来存放一般性数据的AX,BX,CX,DX寄存器被称为通用寄存器
8086CPU的四个通用寄存器都可以分为两个独立的八位寄存器使用(兼容性)
如:
需要注意的是,在作为两个八位寄存器使用时,超出范围的数据不会进一到高位中去
1.2 有关物理地址
8086CPU访问内存时需得到内存单元的地址。而在8086机中,所有内存单元构成一个一维的线性空间,此即为物理地址。
8086CPU给出物理地址的方法: 1.8086有20位地址总线,可传送20位地址,实际上的寻址能力为1M 2.8086内部为16位结构,它只能传送16位的地址,理论上表现出的寻址能力却只有64K 3.问题:8086CPU如何用内部16位的数据转换成20位的地址? 1.8086CPU采用一种在内部用两个16位地址合成的方法,来形成20位的物理地址 即:段地址+偏移地址=物理地址 2.地址加法器合成物理地址的方法: 物理地址=段地址×16+偏移地址 3.“地址段×16”即是数据左移4位(二进制位的左移4位,十六进制的左移1位) 在地址加法器中,如何完成“段地址×16”? 二进制形式的段地址左移4位
需注意:
1.段地址必然是16的倍数,即一个段的起始地址必然是16的倍数 2.偏移地址为16位,16位地址的寻址能力为64K,所以一个段的长度最大为64K 3.CPU可以用不同的段地址和偏移地址形成同一个物理地址
且段为虚拟概念,实际存在并不
1.3 段寄存器
故名思义,存段地址的寄存器
8086有四个段寄存器
CS to IP(指令指针寄存器)
CS和IP寄存器是最关键的寄存器,他们指示了8086CPU当前读取指令的地址
8086CPU工作过程的简要描述 1.从CS:IP指向内存单元,读取指令,读取的指令进入指令缓冲器 2.IP=IP+所读取指令的长度,从而指向下一条指令 3.执行指令,转到步骤1,重复这个过程
CS:IP就好比吃饭的筷子
CS:IP寄存器的初始指向地址为FFFFh和0000h
注意:1.在CPU中,程序员能够【用指令读写】的部件只有【寄存器】, 程序员可以通过改变寄存器中的内容实现对CPU的控制 2.CPU从何处执行指令是由CS、IP中的内容决定的,程序员可以通过改变CS、IP中的内容 控制CPU执行目标指令 3.如何修改CS和IP? 1.通过mov改变AX等,但是不能通过mov改变CS和IP 2.【jmp 段地址:偏移地址】 可以用来同时修改CS和IP 指令中的段地址修改CS 偏移地址修改IP 3.【jmp 某一合法的寄存器】 仅修改IP的内容 比如:jmp ax 或者 jmp bx(类似于mov IP ax) 4.jmp是只具有一个操作对象的指令
1.4 代码段
1.可以将长度为N(N<=64KB)的一组代码,存放在一组地址连续、其实地址为16的倍数的内存单元中 这段内存是用来存放代码的,从而定义了一个代码段 2.CPU中只认被CS:IP指向的内存单元中的内容为指令
有关栈
8086CPU提供了栈操作机制:
在SS,SP中存放栈顶的段地址和偏移地址;提供入栈和出栈指令,它们根据SS:SP指示的地址,按照栈的方式访问内存单元。
Achtung!
任意时刻,SS:SP指向栈顶元素
8086CPU只记录栈顶,不记录栈空间大小,因此在8086环境下栈空间大小需由我们自己管理
PUSH UND POP
push&pop指令的执行步骤
push与pop指令的执行分为两步:
push:第一步:改变sp(sp-2) 第二步:向sssp指向的地址传送数据
pop:第一步:读取sssp地址处的数据 第二步:改变sp(sp+2)
push&pop指令的格式:
push/pop寄存器:
pop xx
push xxpush段寄存器:将一个段寄存器中的数据入栈
pop段寄存器:出栈,用一个段寄存器接收出栈的数据
just like:
push ds
pop espush内存单元:将一个内存单元处的字入栈(栈操作均以字为单位)
pop内存单元:出栈,用一个内存字单元接受出栈数据
just like:
push [0]
pop [2]指令执行时,CPU要知道内存单元的地址,可以在push、pop指令中给出内存单元的偏移地址,段地址在指令执行时,CPU从ds中取得。
Achtung!
pop栈数据后数据不会被剪切而是复制到目标寄存器中
pop后被pop数据芝士理论上从栈里出去了,实际依然存在,直到下一次针对该栈帧push进新的数据
总结:push&pop指令实质上就是一种内存传送指令,可以在寄存器和内存之间传送数据,与mov指令不同的是,push和pop指令访问的内存单元的地址不是在指令中给出的,而是由SS:SP给出的。此外,push和pop指令还会改变SP寄存器的内容。
栈段
对于8086机,编程时可据需要将一组内存单元定义为一个段。zr4,我们可以将长度不大于64K的一组地址连续,起始地址为16的倍数的内存单元当作栈来使用,从而定义了一个栈段。但是,这只是一种人为的安排,CPU并不会因此就实际上的在内存中创建一个栈,CPU只会在执行push,pop等栈操作指令时自动的将我们定义的栈段当作栈空间来访问。
栈顶越界问题
通过之前的学习,已经了解到可以通过SS:SP指针规定pop和push时操作的栈帧(即栈顶),也知道了栈顶的最大变化范围是0~FFFFH,但是这仍然无法解决一个问题:
当栈满或栈空时push或pop,会发生什么呢?
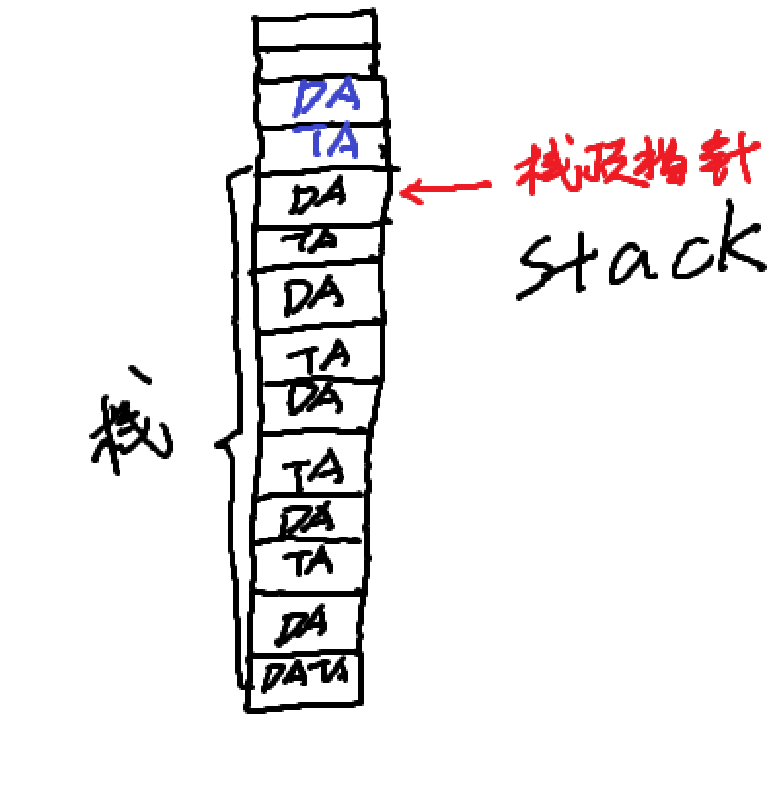
如图所示,当栈满时继续push数据,数据将覆盖栈顶栈以外(照8086,大端)的数据(图中蓝色)
当栈空时继续pop,栈底以外的数据将会被pop走(反之小端)
因而,不难发现,若是在操作栈时不加以检查,很可能导致栈以外空间的数据被意外覆盖/获取
那么此时,SP指针会如何变化呢?
出栈后。SP+2
SP原来为FFFEH,+2后SP=0,所以,当栈为空的时候,SS=1000h,SP=0。
所以,栈顶的变化范围是0~FFFFH,从栈空时SP=0持续压栈,直到栈满时SP又=0,若此时再次压栈,栈顶将环绕覆盖原来栈中内容。
First Program,Go!
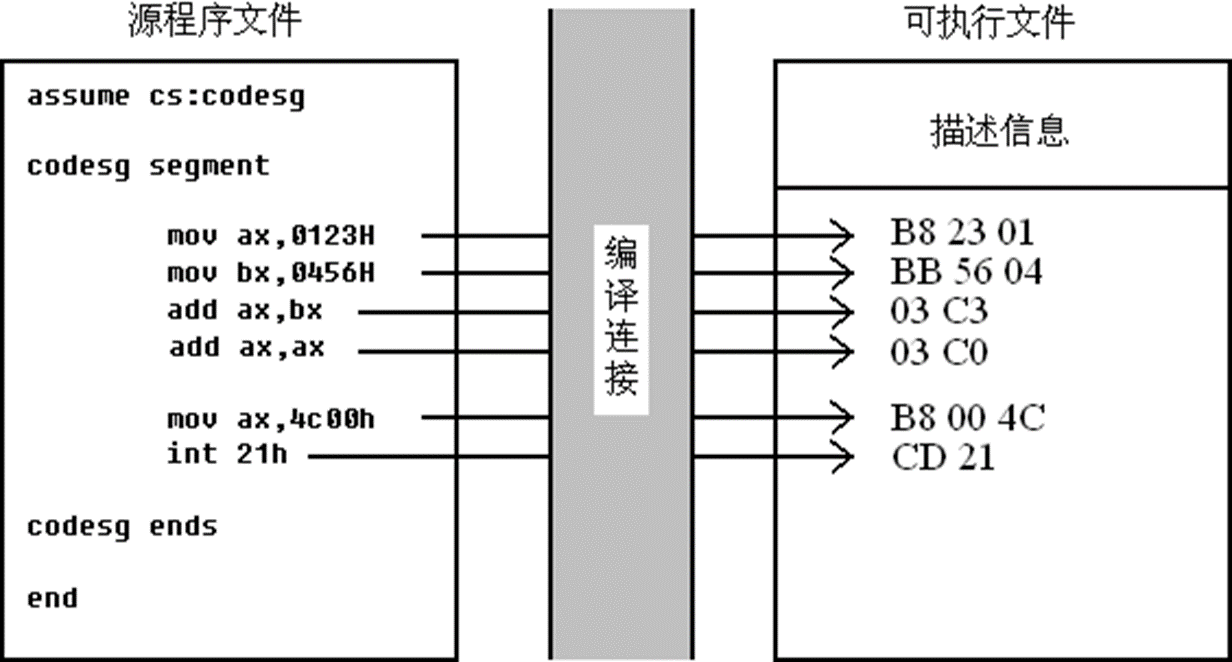
一个汇编语言源程序从写出到最终执行的过程:
编写->编译连接->执行
元程序
assume cs:codesg
codesg segment
start: mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
mov ax,4c00H
int 21h
codesg ends
end源程序中有两种指令:
一种是诸如上面代码中mov,add的汇编指令,这类指令有对应的机器码,能被计算机直接识别。
另一种是诸如assume segment/ends的指令,这种指令被称为伪指令,不难被机器识别但可以被编译器识别,用于指导编译器进行相关编译工作。
SEGMENT/ENDS(定义一个段)
segment/ends是用来定义一个段的伪指令,它是编写汇编程序必须用到的伪指令
功能:
segment:说明一个段开始
ends:说明一个段结束
一个段必须有一个名称来标识,其格式为:
段名 segment
段名 ends
一个汇编程序由多个段组成,用来存放代码、数据、栈空间等(见上文),一个有意义的汇编程序至少要有一个段,用于存放代码。
END(真正的结束)
end指令是一个汇编程序的结束标记,若编译器在编译汇编程序的过程中碰到了伪指令end,就结束对源程序的编译,zr4,若一个程序写完了,一定要在结尾处加上伪指令end,否则,编译器无法知道程序在何处结束。
Achtung!
end与ends的区别:
end:汇编程序的结束标记
ends:一个段的结束标记,与segment成对出现
ASSUME(寄存器和段的关联假设)
assume假设某一段寄存器和程序中的某一个segment...ends定义的段相关联
通过assume说明这种关联,在需要的情况下,编译程序可以将段寄存器和某一具体的段相联系
程序&源程序
我们将源程序文件中的所有内容称为(源程序)
将源程序中最终由计算机执行处理的指令或数据称为(程序)
程序最先以汇编指令的形式,存储在源程序中,后经过(如上文所述流程)编译->连接转变为机器码,存储在可执行文件中
标号&段名称
形如上文代码中
assume cs:codesg
codesg segment
start: mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
mov ax,4c00H
int 21h
codesg ends
end”codesg“的被称为标号/段名称,置于segment/ends前,该段名称最终会被汇编、连接程序处理为一个段的段地址
DOS系统中的程序运行
众所周知,DOS系统是个单任务操作系统,这意味着DOS系统同时最多只能运行一个程序。若要执行第二个程序,则需要先”暂停“第一个程序,将CPU的控制权转交给下一个程序。
该程序运行完后,则又需要将CPU的控制权交还给第一个,也就是让它得以运行的程序,这个过程就被称为:
程序返回
上述代码中诸如
mov ax,4c00H
int 21h实现的就是程序返回功能
Achtung!有关int指令
int指令是X86汇编语言中最重要的指令之一。它的作用是引发中断,调用“中断例程”(interrupt routine)。本文将介绍int指令的基本原理和应用,以及BIOS和DOS系统的中断例程。
一、int指令的原理
1,指令原型
int n
注: 1)n 表示中断号,也可以称为中断类型码。n是一个字节大小的正整数,范围为“0 - 255”。
2)执行“int n”时,CPU从中断向量表中,找到第n号表项,修改CS和IP
(IP)=(n*4),(CS)=(n*4+2)3)对8086PC,中断向量表指定放在内存地址0处(地址固定),共1024个字节。每个表项占两个字,低字存放偏移地址,高字存放段地址。
2,int指令执行过程
1)取中断类型码n;
2)标志寄存器入栈(pushf),IF=0,TF=0(重置中断标志位);
3)CS、IP入栈;
4)查中断向量表, (IP)=(n4),(CS)=(n4+2)。
3,中断例程的返回
中断例程既可以直接返回dos,如下mov ax,4c00h int 21h
中断例程也可以像子程序一样返回到中断产生的地方,这时,就需要用到“iret”——中断返回指令。
iret指令的汇编语法描述为:pop IP pop CS popf
iret指令与int相对,它会恢复原始的CS和IP值,并恢复标志寄存器的值。编译&连接
我们都知道编译是将源程序汇编码翻译成机器码的重要过程,那么,连接(LINK)起什么作用呢?
在实际运行中,源程序往往会很大或调用了多个库文件中的子程序,因此需要连接:
连接的作用&情景
当源程序很大时,可以将他们分成多个源程序文件夹编译,每个源程序编译成为目标文件后,再用连接程序将它们连接在一起,生成一个可执行文件。 当程序中调用了某个库文件中的子程序,需要将这个库文件和该程序生成的目标文件连接到一起,生成一个可执行文件 一个源程序编译后,得到了存有机器码的目标文件,目标文件中的有些内容还不能直接用来生成可执行文件,连接程序将这些内容处理为最终的可执行信息。所以在只有一个源程序文件,而又不需要调用某个库中的子程序的情况下,也必须用连接程序对目标文件进行处理,生成可执行文件
可执行文件中的程序装入内存并运行的原理
在DOS系统中,可执行文件中的程序P1若要运行,必须有一个正在运行的程序P2将P1从可执行文件中加载入内存,将CPU的控制权交给P1,P1才能得以运行,当P1运行完毕后,应该将CPU的控制权交还给使他得以运行的程序。
操作系统的外壳
操作系统是由多个功能模块组成的庞大、复杂的软件系统。任何通用的操作系统,都需要提供一个shell(外壳)程序,两脚通过使用这个程序来操作计算机系统工作。DOS系统中的shell是程序command.com,also as known as CMD.
下面以执行O.exe为例说明运行可执行文件的流程
1.当在DOS中直接执行可执行文件O.exe时,由正在运行的cmd.exe将1.exe中的程序加载入内存(若以debug模式打开,则是cmd->debug->O)
2.cmd.exe设置CPU的CS:IP指向程序的第一条指令(即程序的入口)从而使得程序得以运行
3.程序的运行结束后,返回cmd.exe中,CPU继续运行cmd.exe(or debug)
[BX]&loop
先从一段简单的代码开始本节
assume cs:codesg
codesg segment
asm23: mov ax, 2000h
mov ds, ax
mov al, [0]
mov bl, [1]
mov cl, [2]
mov dl, [3]
mov ax, 4c00h
int 21h
codesg ends
end asm23不难看出,在这段代码中,诸如[0] [1] [2]的字代表内存单元,他的偏移地址为0;
注意,在使用编辑器写汇编的时候不能这么写,会被直接识别为
mov al, 0 而非 mov al, [0]
该写法仅在debug模式中生效...
[bx]与内存单元的描述
而[bx]也是如此,和[0]类似,[bx]也代表一个内存单元,它的段地址在DS中,它的偏移地址在bx中,取字或字节取决于它放入的寄存器是8位还是16位,由此我们不难看出,要完整的描述一个内存单元,需要两种信息:
(1)内存单元的地址;
(2)内存单元的长度(类型)。
现在在回到上面的注意中,我们该怎么样实现同 mov al, [0]的效果呢?
mov bx, 0
mov al, [bx]问题5.1
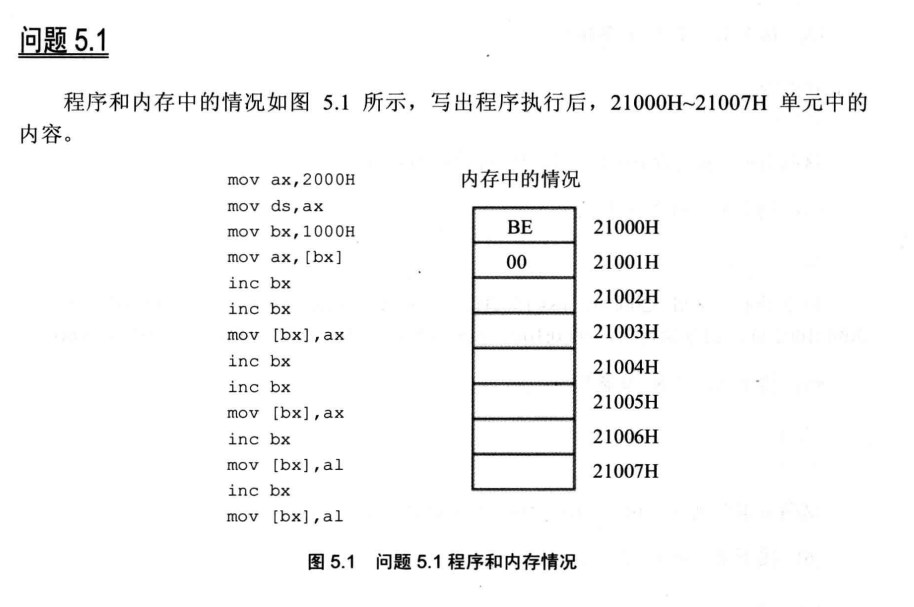
先用湿件计算机跑一下
mov ax,2000hax被赋值为2000
mov ds,axds段寄存器被赋值为ax寄存器内容,此时ds指向2000
mov bx,1000hbx为1000
mov ax,[bx]ax被赋值为偏移地址为1000处的内容,即be
inc bx
inc bxbx自增2,偏移地址指向1002
mov [bx],ax2000:1002处被更改为be
inc bx
inc bx同理,来到1004
mov [bx],ax1004变为be
inc bx来到1005
mov [bx],al[bx]变为ax低八位内容,即偏移地址指向be
inc bx自增,指向bf
mov [bx],al再次指向be
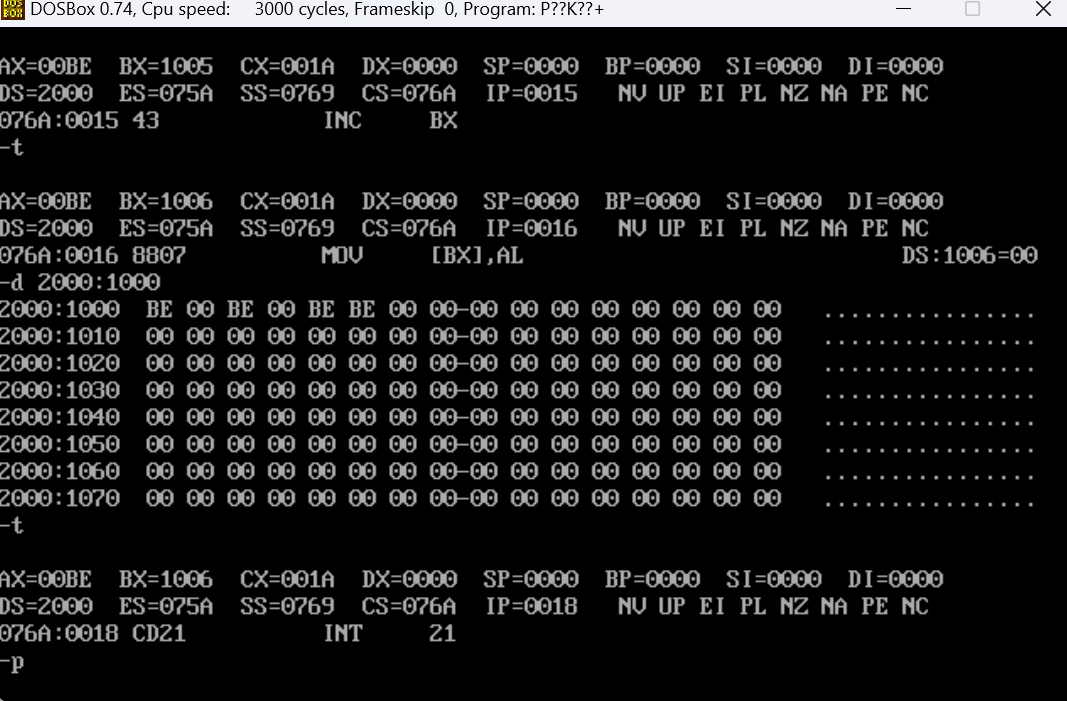
可以看到结果是一致的
loop指令
口圭,是循环!
还是从一段程序开始本节
assume cs:codesg
codesg segment
no24: mov ax,2
mov cx,11
s: add ax,ax
loop s
mov ax,4c00h
int 21h
codesg ends
end no24不难看出这段程序的功能是实现a的十二次自增运算,使用了诸如
s: add ax,ax
loop s的结构来实现执行11次同样的操作
其结构与do while循环类似
下面是有关loop的基本信息
1.指令格式:loop 标号
CPU执行loop指令的时候,要进行两步操作
1.(cx)=(cx)-1;
2.判断cx中的值,若不为零,则转至标号处执行程序
若为零,则向下执行。
2.通常,loop指令实现循环,cx中存放循环的次数
3.标号
在汇编语言中,标号代表了一个地址,标号标识了一个地址
4.使用cx和loop指令相配合实现循环功能的三个要点
1.在cx中存放循环次数
2.loop指令中的标号所标识地址要在前面
3.要循环执行的程序段,要写在标号和loop指令的中间
5.用cx和loop指令相配合实现循环功能的程序框架
mov cx,循环次数
S:循环执行的程序段
loop s另外一点值得注意的是,在loop中,通用寄存器cx被直接指定成为了专用的循环次数寄存器,这是因为在CPU中,不同的通用寄存器也会有各自的专用功能,如bx被作为段寄存器,cx被作为循环次数寄存器,具体可参见x86汇编手册
由此:在使用loop循环时最好将设置循环次数的语句放在指定循环内容和标号的语句之上,避免cx寄存器被意外更改
问题 5.2

代码:
assume cs:codesg
codesg segment
q52: mov ax,123
mov cx,236
s: add ax,ax
loop s
mov ax,4c00h
int 21h
codesg ends
end q52若要提高运行速度,可交换123,236以减少循环次数
Debug中跟踪用loop指令实现的循环完成
注意:在汇编中数据不能以字母开头,若要输入诸如fffh这样的数要在头前加0
在前面我们发现了如果要单步调试一个循环的话,使用t命令是不合适的,因此我们
在debug程序中引入G命令和P命令 1.G命令 G命令如果后面不带参数,则一直执行程序,直到程序结束 G命令后面如果带参数,则执行到ip为那个参数地址停止 2.P命令 T命令相当于单步进入(step into) P命令相当于单步通过(step over)
Debug和汇编编译器Masm对指令的不同处理
1.在debug中,可以直接用指令 mov ax,[0] 将偏移地址为0号单元的内容赋值给ax 2.但通过masm编译器,mov ax,[0] 会被编译成 mov ax,0 1.要写成这样才能实现:mov ax,ds:[0] 2.也可以写成这样: mov bx,0 mov ax,[bx] ;或者mov ax,ds:[bx]
此为间接寻址
若一定要在编译器中使用诸如[0]的偏移地址寻址,可在其前加上段地址:
mov ax,ds:[0]loop和[bx]的联合应用
在问题5.3中(不要问我为什么没写5.3,问就是懒)
前情提要:问题5.3
计算ffff:0~ffff:b单元中的数据的和,结果存储在dx中
我们注意到,12个八位数据加一块,最后的结果可能会超出八位,造成越界,因此,我们当用16位寄存器存放结果;将一个八位数据放入16位寄存器中,因为类型的不匹配,会造成其不能与16位数据相加的问题。
那么?
解决办法
将八位数据先赋值给ax转换为16进制数据
assume cs:codesg
codesg segment
start:
;指定数据段
mov ax,0ffffh
mov ds,ax
;初始化
mov ax,0
mov dx,0
mov bx,0
;指定循环次数,12次
mov cx,0ch
circ:
;把8位数据存入al中,即ax中存放的是[bx]转化之后的16位数据,前8位都是0
mov al,[bx]
;进行累加
add dx,ax
;bx自增,变化内存的偏移地址
inc bx
loop circ
;程序返回
mov ax,4c00h
int 21H
codesg ends
end start 段前缀
1.指令“mov ax,[bx]”中,内存单元的偏移地址由bx给出,而段地址默认在ds中 2.我们可以在访问内存单元的指令中显式地给出内存单元的段地址所在的段寄存器 比如 mov ax,ds:[0] mov ax,ds:[bx] 这里的ds就叫做【段前缀】
不要问我为什么突然来这么一段莫名奇妙的解释,问就是水字数
一段安全的空间
1.8086模式中,随意向一段内存空间写入内容是很危险的 因为这段空间中可能存放着【重要的系统数据或代码】 2.在一般的PC机中,DOS方式下,DOS和其他合法的程序一般都不会使用【0:200~0:2FF】 的256个字节的空间。所以,我们使用这段空间是安全的
段前缀的使用
包含多个段的程序
引:
在前几章中,我们为了方便理解与阅读,将所有代码都放在一个段里执行,这也是为什么在连接时会报warning:no stack segment。从本章开始我们将学习编写包含多个段的程序。
在代码段中使用数据
1.dw的含义【定义字型数据:define word,16字节】 在数据段中使用dw定义数据,则数据在数据段中 在代码段中使用dw定义数据,则数据在代码段中 堆栈段也是一样 2.在程序的第一条指令前加一个标号start,并且这个标号在伪指令end后面出现 可以通知编译器程序在什么地方结束,并且也可以通知编译器程序的入口在哪里
在代码段中使用栈
试想,若要想逆序存储一段数据,该如何实现?
可以利用上文所提到过的栈的“先进后出,后进先出”的性质,将一段数据依次入栈再出栈即可实现。
由此可以引出在代码段中使用栈。
assume cs:codesg
codesg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
dw 0,0,0,0,0,0,0,0
no30stack: mov ax,cs
mov ss,ax
mov sp,32
mov bx,0
mov cx,8
s: push cs:[bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop cs:[bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
codesg ends
end no30stack在这段程序中,我们就是通过dw向系统申请一段空间,再把它当作栈来使用
将数据、代码、栈放入不同的段
在前面的两个小节中,我们都是使用一个段来存储包括数据代码栈在内的不同数据,在这种编程模式下,我们需要时刻注意何处是数据,何处是栈,何处是代码。
这样做显然有两个问题
1.把它们放在一个段中程序会显得很是混乱
2.8086下一个段的容量不会大于64KB,前面用到的空间很小,数据很少,用一个段来存放也可以,但并不是所有程序都能限制在64kb以内
因此,我们可以使用定义代码段一样的方法来定义多个段,然后在这些段里面定义需要的数据,通过定义数据来取得栈空间
nm,yzmzn?
我们可以在源程序中为这三个段起具有含义的名称
但是,要知道,CPU并不能读懂我们人为指定的名称,因此我们还需要更进一步的操作。
在源程序中使用伪指令
assume cs:codesg,ds:datasg,ss:stacksg在这行代码中,我们使用assume这个伪指令来将cs,ds,ss与codesg datasg,stacksg相关联,但是要注意到,assume是个伪指令,只能被编译器识别而不能被CPU识别,因此,真正要想定义多个段,我们应当:
使用end指令结合标号定义多个段
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
=========random content==========
datasg ends
stacksg segment
=========random content==========
stacksg ends
codesg segment
start:
=========random content==========
=========random content==========
=========random content==========
int 21h
codesg ends
start end像这样,我们就可以使CPU按照我们的安排行事,使用机器指令控制使其能够正确的识别代码、数据、栈段。
注意:
需在在code段中给DS,CS、SS设置相应的值才能让CPU识别出数据段、代码段、堆栈段 其中汇编程序开始的地方(即代码段开始的地方)由end后面的标号所指向的地方给出
assume指令不可省略!
实验五 编写、调试具有多个段的程序

assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
datasg ends
stacksg segment
dw 0,0,0,0,0,0,0,0
stacksg ends
codesg segment
expfunf: mov ax,stacksg
mov ss,ax
mov sp,16
mov ax,datasg
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
codesg ends
end expfunf
exp2
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
dw 0123h,0456h
datasg ends
stacksg segment
dw 0,0
stacksg ends
codesg segment
expfunf2: mov ax,stacksg
mov ss,ax
mov sp,16
mov ax,datasg
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
codesg ends
end expfunf2
exp5

assume cs:codesg
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
codesg segment
funf5: mov ax,c
mov es,ax
mov ax,a
mov ds,ax
mov ax,b
mov es,ax
mov bx,0
mov di,0
mov cx,8
s: mov al,ds:[bx]
add al,es:[bx]
mov es:[si],al
inc bx
inc si
loop s
mov ax,4c00h
int 21h
codesg ends
end funf5
更灵活地定位内存地址
引:本章主要讲解一些更灵活的定位内存地址的方法和相关的编程方法
and和or指令
and指令:逻辑与指令,按位进行与运算
如:
mov al,01100011b
and al,00111011b
--------------->
al=00100011b通过and指令可以将操作对象的相应位设置为0,其他位保持不变
例如al的第6位设为0,and al,10111111b
例如al的第7位设为0:and al,01111111B
例如al的第0位设为0:and al,11111110B
or指令,逻辑或运算,按位进行或运算
如:
mov al,01100011b
or al,00111011b
--------------->
al=01111011b通过该指令可将操作对象的相应位设为1,其他位不变 or al,01000000B;将al的第6位设为1 or al,10000000B;将al的第7位设为1 or al,00000001B;将al的第0位设为1
ASCII码
无需多言
以字符形式给出的数据
在汇编程序中,可以使用‘xxx’的方式指明数据是以字符的形式给出的,此时编译器会将它们转化为相应的ASCII码,例如:
db 'unIX' ;相当于db 75h,6eh,49h,58h,分别对应四个字符的ASCII码
mov al,'a' ;相当于mov al,61h,同理对应ASCIIASCII码中,大写字母和小写字母之间的规律:
小写字母=大写+32=大写+20h
大小写转换问题
1.方案一:
1.识别出是该字节是表示一个的大写英文字符,还是小写的
用于条件判断的汇编程序,目前还没有学到
2.根据+20H 或者 -20H进行大小写转换
2.方案二:
1.若全部转化为大写,则将第5位置0
and al,11011111B
2.若全部转化为小写,则将第5位置1
or al,00100000B[bx+常数]
一种间接寻址方式,好处是可以帮助快速找到某个地址某个偏移处,例如:
mov ax,[bx+200]其含义为:将一个内存单元的内容送入ax,这个内存单元的长度为2字节,存放入一个字单元,该字单元的偏移地址为bx中的数值加上200,段地址在ds中,亦可以写成:
mov ax,200[bx]
-------or--------
mov ax,[bx].200用[bx+idata]的方式进行数组的处理
Q:在codesg中填写代码,将datasg中定义的第一个字符串转化为大写,第二个字符串转化为小写
A:我们观察datasg段中的两个字符串,一个的起始地址为0,另一个的起始地址为5.
我们可以将这两个字符串看作两个数组,一个从0地址开始存放,另一个从5开始存放
我们可以用[0+bx]和[5+bx]的方式在同一个循环中定位这两个字符串中的字符
注意这个数组的定位方式,对比C语言 C语言的数组定位方式:a[i],b[i], a、b是地址常量 汇编语言的数组定位方式:0[bx],5[bx] 所以:[bx+常数]的方式为高级语言实现数组提供了便利的机制
code:
assume cs:codesg,ds:datasg
datasg segment
db 'BaSiC'
db 'MinIX'
datasg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,5 ;做5次循环
circ:
mov al,[bx]
and al,11011111b
mov [bx],al
mov al,[bx+5];等价于mov al,5[bx];等价于mov al,[bx].5
or al,00100000b
mov 5[bx],al
inc bx
loop circ
mov ax,4c00h
int 21h
codesg ends
end startSI和DI
在前面的学习中,我们已经学习并使用过了AX,BX,CX,DX,DS,CS,SS,ES,IP,SP十个寄存器,这一节我们将来学习SI,DI两个寄存器
有关SI,DI
SI和DI是8086CPU中和bx功能相近的寄存器(因为bx不够用所以才有了SIDI)
但与bx不同的是,SI&DI寄存器虽都是16位,但却不能够分成两个8位寄存器来使用
SI,DI是16位寄存器,循环中自增时应当+2
以下三组指令展现了SI,DI,BX寄存器具有相同的作用
mov bx,0
mov ax,[bx]
mov si,0
mov ax,[si]
mov di,0
mov ax,[di]同理,
mov bx,0
mov ax,[bx+123]
mov si,0
mov ax,[si+123]
mov di,0
mov ax,[di+123]值得注意的是,同如通用的通用寄存器一样,SIとDI寄存器也有通常意义上的作用:
通常用ds:si指向要复制的源始字符串 通常用ds:di指向要复制的目的空间
复习:
AX:通常用于累加,accumulator register
BX:通常用于存放基地址/偏移地址,base register
CX:通常用于计数,count register
DX:通常用于存放数据,data register
Q:用寄存器SI和DI实现将字符串'welcome to masm!'复制到它后面的数据区中
assume cs:code,ds:data
data segment
db 'welcome to masm!'
db '................'
data ends
code segment
start:
mov ax,data
mov ds,ax
mov si,0
mov di,16
mov cx,8
circ:
mov ax,0[si]
mov [di],ax
inc di
inc di
inc si
inc si
loop circ
mov ax,4c00h
int 21h
code ends
end start[bx+si]和[bx+di]
刚刚了解完si和di,不妨利用起来!
[bx+si]/[bx+di]表示一个内存单元,它的偏移地址为bx中的数值加上si中的数值,它的偏移地址也在ds中
[bx+si]也可写成[bx] [si]
[bx+si+常数]和[bx+di+常数]
不难理解,[bx+si+常数]/[bx+di+常数]表示一个内存单元,偏移地址为bx的值+si/di的值+常数
指令mov ax,[bx+si+常数]也可以写成如下形式
mov ax,200[bx+si]
mov ax,200[bx][si]
mov ax,[bx].200[si]数据处理的两个基本问题
本章对于前面所学内容是总结性的
引:
计算机是进行数据处理、运算的机器,那么有两个基本的问题就包含在其中: 1.处理的数据在什么地方? 2.要处理的数据有多长? 这两个问题,在机器指令中必须给以明确或隐含的说明,否则计算机就无法工作
bx,si,di,bp
在8086CPU中,只有bx,bp,si,di四个寄存器可以用在[...]中,用来进行内存单元的寻址,它们四个都可以单独出现在[...]中,或者以以下四种组合出现:
错误组合:
有关bp
只要在[...]中使用寄存器bp,且指令中没有显性(或者说强制)给出段地址,那么段地址就默认在ss中,例如:
ax的值为栈空间中偏移地址为bp的内存单元
mov ax,[bp]
mov ax,[bp+常数]
mov ax,[bp+si]
mov ax,[bp+si+常数]机器指令处理的数据所在位置
在本章引中我们提到,CPU处理数据需要地址和长度,那么,机器指令呢?它处理的数据所在位置在哪里呢?
绝大部分机器指令进行数据处理的指令可分为3大类
读取、写入、运算
在机器指令这一层,数据的值是几何并不重要,它只关心指令执行前一刻它所将要处理的数据所处的位置
指令在执行前,所要处理的数据可以在三个地方
CPU内部(寄存器)、内存、端口
汇编语言中数据位置的表达
汇编语言中用三个概念来表达数据的位置
1.立即数
2.寄存器
3.段地址SA和偏移地址EA
存放地址的寄存器可以是默认的,既可以是默认在ds中,也可以是在ss中(通过使用bp)
存放地址的寄存器也可以人为强制指定(即显性给出)
mov ax,ds:[bp]
mov ax,es,[bx]
mov ax,ss:[bx+si]
mov ax,cs:[bx+si+8]🦜
寻址方式
🦜🦜🦜🦜🦜如果看到这里,恭喜你发现了彩蛋!🦜🦜🦜🦜🦜
aGlud Dp3aG F0IGl zIElu dGVyZ 2VyIE 92ZXJ mbG93 Pw==
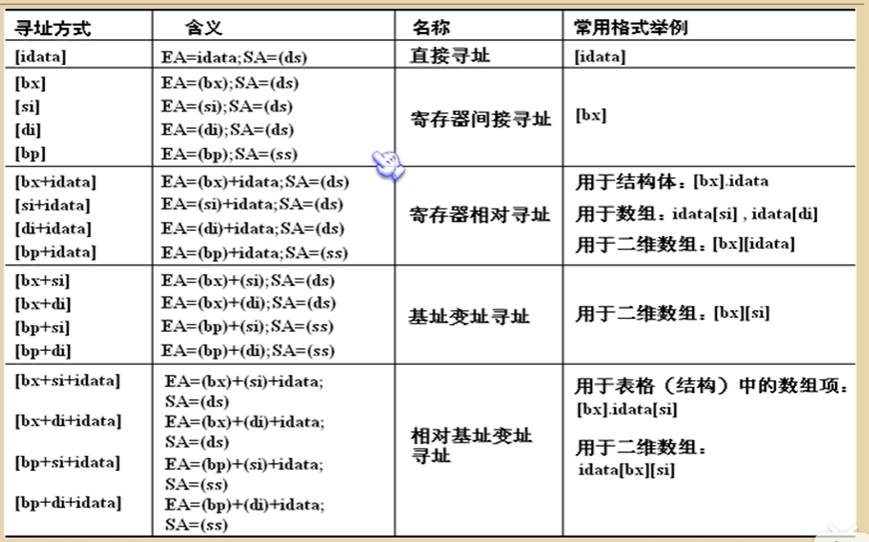
直接寻址:用常量表示偏移地址
寄存器间接寻址:用[bx]存放偏移地址,再读取bx内容
寄存器相对寻址:用[bx]和常量共同表示偏移地址
基址变址寻址:用诸如[bx+si]等可在[..]内的寄存器联合表达
相对基址变址寻址:比前者再多一个常量💢
指令要处理的数据有多长?
8086CPU的指令可以处理两种尺寸的数据:byte 和 word
因此机器指令中必须要明确指令进行的是字操作还是字节操作
8086CPU确定数据长度的几种方法
1.通过寄存器名指明要处理的数据的尺寸
mov al,1 ;byte
mov bx,ds:[0] ;word2.在没有寄存器名存在的情况下,用操作符X ptr指明内存单元的长度(X 可以是word 或 byte,当然之后(之前?)还有qword 和 dword 等)
诸如:
mov byte ptr ds:[0],1
inc byte ptr [bx]
inc byte ptr ds:[0]
add byte ptr [bx],2或
mov word ptr ds:[0],1
inc word ptr [bx]
inc word ptr ds:[0]
add word ptr [bx],23.其他方法
有些指令默认了访问的内存单元类型:
pop和push指令一定操作的是word型数据
在没有寄存器参与的内存单元访问指令中,用word ptr或者byte ptr显性地指明所要访问的内存单元的长度,是非常有必须要的,否则,CPU无法得知所要访问的单元是字单元,还是字节单元
寻址方式的综合应用
在上面我们介绍了四种直接寻址意外的寻址方式,不难看出这四种寻址方式通过寄存器,常量的组合实现了丰富、且更加结构化的寻址方式,这对我们之后处理结构化的数据提供了便利(且听下回分解)。
div指令
div,故名(division)思义,是除非指令,但在8086机中,使用div作除法的时候,要求:
除数:8位或16位,在寄存器或内存单元中
被除数:(默认)放在AX或DX和AX中
除数与被除数的相互关系
结果存放的位置
div指令格式
div 寄存器
或
div 内存单元👆除数是寄存器或内存单元的内容
div指令示例
div byte ptr ds:[0] ;被除数是16位,除数是ds:[0]的内容(8位)
解析:
(al)=(ax)/((ds)*16+0)-->es ist 商
(ah)=(ax)/((ds)*16+0)-->es ist 余数div word ptr es:[0] ;被除数是32位,除数是es:[0]的内容(16位)
解析:
(ax)=[(dx)*10000h+(ax)]/((es)*16+0)-->es ist 商
(dx)=[(dx)*10000h+(ax)]/((es)*16+0)-->es ist 余数练:

assume cs:codesg,ss:stacksg,ds:datasg
datasg segment
dd 100001;4b-0-32
dw 100;2b-32-16
dw 0;2b-48-16
datasg ends
codesg segment
divdd: mov ax,datasg
mov ds,ax
mov ax,ds:[0]
mov dx,ds:[2]
div word ptr ds:[4]
mov ds:[6],ax
mov ax,4100ch
int 21h
codesg ends
end divdd伪指令dd
没错这个看起来很像dw,db的伪指令就是用来定义双字型数据的
示例:
data segment
db 1 ;字节型数据
dw 1 ;字型数据
dd 1 ;双字型数据
data ends
dup
dup是一个操作符,在汇编语言中,同db、dw、dd等一样,也是有编译器识别处理的符号
dup和db、dw、dd等数据定义伪指令配合使用的,用来进行数据的重复
dup示例:
db 3 dup(0) ;定义了3个字节,它们的值都是0
db 3 dup(0,1,2) ;定义了9个字节,它们都是0、1、2、0、1、2、0、1、2
db 3 dup('abc','ABC') ;定义了18个字节,相当于db'abcABCabcABCabcABC'
dup的使用格式
db 重复的次数 dup(重复的字节型数据)
dw 重复的次数 dup(重复的字型数据)
dd 重复的次数 dup(重复的双字型数据)
实验七 寻址方式在结构化数据访问中的应用(tbc)
别急,等我三刷再补这块的笔记
转移指令的原理
8086转移指令的简单分类
1.无条件跳转指令,诸如jmp
2.条件跳转指令,诸如jz,ja
3.循环指令,诸如loop
4.过程跳转指令,belike func in c
5.中断,这个不太了解,但是之后会了解的
应该不会有人看到这里吧Ψ( ̄∀ ̄)Ψ,那我在这里小小发个电
You↑say↓~the price of my luv not the price y'all willing to pay↓~
You↑cry~~In your tea!which you hurl in the sea when you see me go by~
Why↓so↑sad?
Remember we made an arrrrrrrrrangement when you wen~taway
操作符offset
操作符offset在汇编语言中由编译器处理,它的功能是取标号的偏移地址
如:
s: mov ax,offset s那么此时存入ax的值就是s标号在codesg中的偏移地址
复习:
标号是什么?
标号是人为规定给编译器看的用来标记一段代码的符号,实际调试中会表现为分配给这段代码的段地址,标号可以是任何样子,比如前文的expfunf,或者小甲鱼老师的s,s0
jmp指令
此为无条件跳转指令,可以只修改ip的值,也可以同时修改cs和ip的值,示例:
jmp 段地址:偏移地址可以用来同时修改CS和IP。指令中的段地址修改CS,偏移地址修改IP 但这种用法编译器不认识,只能做在debug中使用
jmp 某一合法寄存器仅修改IP的内容,比如jmp ax,等效于mov IP ax
依据位移进行转移的jmp指令
jmp short 标号段内短转移,它对ip的修改范围为-128~127,也就是说,它向前转移可以最多越过128个字节(负数,补码),向后可以最多越过127个字节
CPU不需要目的地址就可以实现对ip的更改
在查看jmp short的机器码时,我们可以发现在其机器码中不存在与目标地址相关的数字,这是因为jmp short的跳转是通过在源地址的基础上加上一个偏移量来实现的,比如:
jmp s存储在2000:0008~0009处
其机器码为EB F6
而S存储在2000:0000~2000:0002处
这时的f6就被作为便宜量直接加到ip上,实现“-10”的操作另一种与jmp short功能类似的指令
jmp near ptr 标号这个指令实现的是段内近转移,其功能为(ip)=(ip)+16位位移(short为八位)

